文丨李安琪
编辑丨李勤
尽管特斯拉从来没有公开过FSD v12版本的技术魔法,但国内确实已经掀起了“端到端”自动驾驶的学习热潮。
作为智驾追赶者的理想汽车,也不例外。7月5日,理想就首次公开了其端到端自动驾驶技术架构。
该架构主要由端到端模型、VLM视觉语言模型、世界模型三部分共同构成。同时,理想还开启了新架构方案的早鸟测试计划。
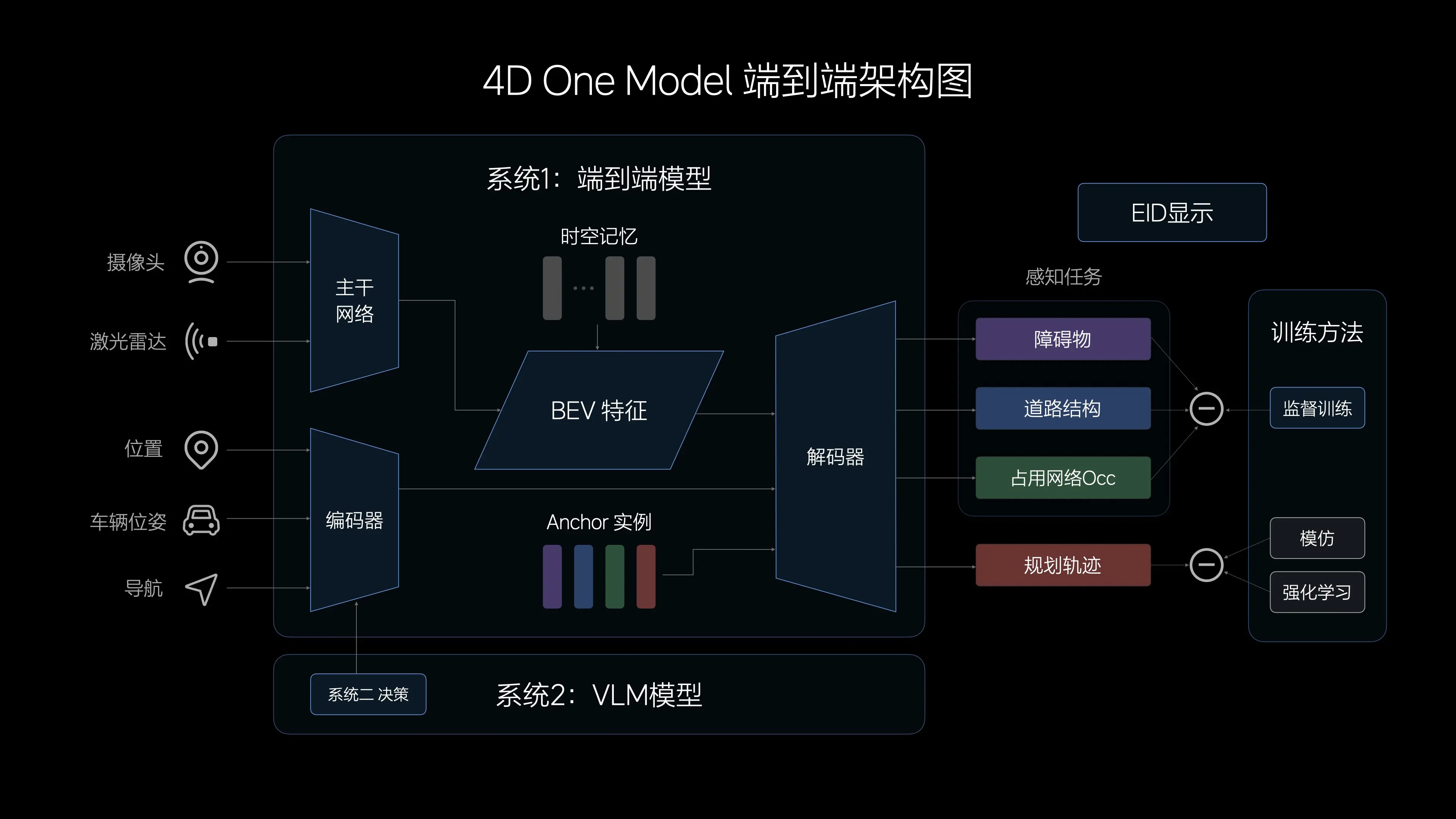
有行业人士指出,跟华为、小鹏的分段式端到端方案相比,理想方案的方案更为激进,可视为分段式端到端的下一站。“从传感器输入到行驶轨迹输出只经过一个模型。”理想智能驾驶技术研发负责人贾鹏在发布会上介绍道。
此外,在新技术架构方案中,理想还融合了视觉语言模型、世界模型,分别帮助智驾解决复杂的城市道路挑战,以及端到端方案测试、验证问题。
理想智能驾驶负责人郎咸朋在社交媒体上表示,端到端方案从去年下半年就在内部孵化并启动预研,目前已经完成了模型的原型验证和实车的部署。
据36氪了解,目前理想针对端到端搭建了一个超300人的研发团队,在北京进行封闭式开发,预计年内拿出阶段性成果。
不少业内人士都表示,智驾行业技术路径切换得太快了,去年行业的主流方案还是轻高精地图的城区智驾,今年就要追击端到端。这也是车企智驾团队的研发难题,上一代方案还没完全落地,下一代方案又将到来。
但在技术切换的空隙,也让过去智驾晚投入的玩家如理想等,有了赶上的机会。至少在端到端方案上,理想与同行站在了相近起跑线上。
比特斯拉后退一步,比“分段式端到端”更进一步
端到端自动驾驶方案,最先由特斯拉引领。在喂给AI神经网络足够多、足够高质量的数据前提下,智驾系统能够自主学习人类的驾驶方式。用特斯拉的话来说,“端到端”就是“输入图像,输出驾驶指令”。
比起传统智驾方案,端到端有更高的技术天花板。过往智驾方案以工程师制定的规则为基础,依靠感知、决策、规划等模块配合来实现智驾。
但每个模块相互独立,模块间的信息传递接口由工程师来定义,这就造成了信息流转的缺失与误差。一方面是影响整体方案的效果,二是依赖人力应对无尽的corner case,并非长久之计。
端到端看起来是一剂良药。特斯拉FSD v12也凭借端到端方案,大杀四方。华为、小鹏、蔚来、Momenta、商汤、元戎启行等,都试图跟上特斯拉的端到端步伐。
而作为国内首个公开端到端技术方案的车企,理想的方案也有值得分析与借鉴之处。
理想提出的端到端“One Model”结构,输入端是传感器信息,输出端是行驶轨迹。不过这个思路并非理想独有。此前,商汤绝影提出的端到端自动驾驶方案UniAD也是类似思路,该模型还拿到了2023年全球顶级计算机视觉会议CVPR的最佳论文奖。
理想认为,由于中间没有规则介入,其端到端模型在信息传递、推理计算、模型迭代上更有优势,可以拥有更强大的通用障碍物理解能力、超视距导航能力、道路结构理解能力,以及更拟人的路径规划能力。
图源:理想汽车
从技术架构上看,理想比华为、小鹏的分段式端到端更近一步。此前华为的提出的端到端方案,仍有感知大网和预决策规划大网。小鹏的端到端方案则分为神经网络感知XNet、规控大模型XPlanner+大语言模型XBrain三段。
不过有行业技术人士告诉36氪,One Model方案的训练也有很大挑战。“以前训练规控,会假定感知模块是完美的,两者独立训练,出了问题也比较容易定位,但端到端方案是感知和规划一起训练,训完容易出现负优化的情况。”
而跟特斯拉号称“输入图像、输出控制”的端到端方案相比,理想的方案显然还少了一步。
目前,在国内,各家的端到端思路,最多也就从感知端到预测决策端,最终的控制执行模块,依然由工程师的手写规则来兜底。
视觉语言模型,帮助智驾理解世界
理想端到端方案,更有意思的地方还在于,提出了快思考与慢思考。这点主要是受诺贝尔奖得主丹尼尔·卡尼曼的“快慢系统理论”启发。
在理想看来,快系统,即系统1,善于处理简单任务,更像人类基于经验和习惯形成的直觉,足以应对驾驶车辆时95%的常规场景。
慢系统,即系统2,则是人类通过更深入的理解与学习,形成的逻辑推理、复杂分析和计算能力,在驾驶车辆时用于解决复杂甚至未知的交通场景,占日常驾驶的约5%。两个系统的,可以分别确保大部分场景下的高效率和少数场景下的高上限。
图源:理想汽车
借鉴这套理论,理想汽车打造了自动驾驶技术架构。系统1由端到端模型实现,实现快速响应,端到端模型接收传感器输入,并直接输出行驶轨迹用于控制车辆。
而系统2由VLM视觉语言模型实现,其接收传感器输入后,经过逻辑思考,输出决策信息给到系统1。双系统构成的自动驾驶能力还将在云端利用世界模型进行训练和验证。
用理想的话来说,VLM模型对物理世界的复杂交通环境具有强大的理解能力。不仅可以识别路面平整度、光线等环境信息;还具备更强的导航地图理解能力,可以配合车机系统修正导航;还能理解公交车道、潮汐车道和分时段限行等复杂的交通规则,在驾驶中作出合理决策。
图源:理想汽车
举个例子,比如车辆前方遇到坑洼路面的时候,系统2就会给出具体驾驶建议,将车速从40公里/小时降到32公里/小时。小鹏的大语言模型XBrain也有类似能力,可以识别待转区、潮汐车道、特殊车道、路牌文字等指令。
作为视觉语言模型,理想的VLM模型参数量达到22亿。当然,这跟ChatGPT等大语言模型的数百上千亿参数无法相提并论。
但理想希望将端到端+VLM双系统同时部署在车端芯片上。为了将双系统部署到车上,理想智驾高级算法专家詹锟也介绍,最早VLM模型在车端的推理时间长达4.1秒,经过不断优化后,目前整体推理性能已经优化了13倍,推理只需0.3秒。
目前,行业主流、已经量产、能够支持端到端方案的智驾芯片只有特斯拉的HW3.0芯片与英伟达的Orin,理想搭载的正是英伟达Orin。不过有行业人士告诉36氪:“像理想这种延时,20亿级的模型参数量算是比较极限了。后续如果要上更大模型,可能就需要Thor(英伟达下一代芯片,算力超1000Tops)了。”
图源:理想汽车
此外,理想还介绍了端到端方案的测试和验证方法。理想介绍,行业过往主要通过虚拟仿真、重建仿真等方式来对智驾做仿真测试。而随着生成式AI的出现,生成式仿真也正成为智驾行业的一大趋势。
理想结合了重建仿真和生成仿真两种技术路径,为端到端的测试验证搭建了一个世界模型。理想称,重建和生成两者结合所构建的场景,可以为自动驾驶系统能力的学习和测试创造了更优的虚拟环境。
图源:理想汽车
不过,理想的端到端+VLM方案还难以真正立刻交付给用户。7月,理想将推送给用户仍然是基于分段式端到端的无图NOA方案,能在全国道路开启。
当下,国内高阶智驾面临商业与技术的双重挑战。一方面是稳步推进的大规模智驾体验,保证用户口碑;另一方面则是跟上端到端等技术浪潮。
这需要车企智驾团队同时具备极强的工程落地、技术判断能力,保证用户体验的同时,持续追赶前沿技术。这对理想是挑战,对华为、对小鹏、蔚来,以及一众智驾供应商而言,同样如此。